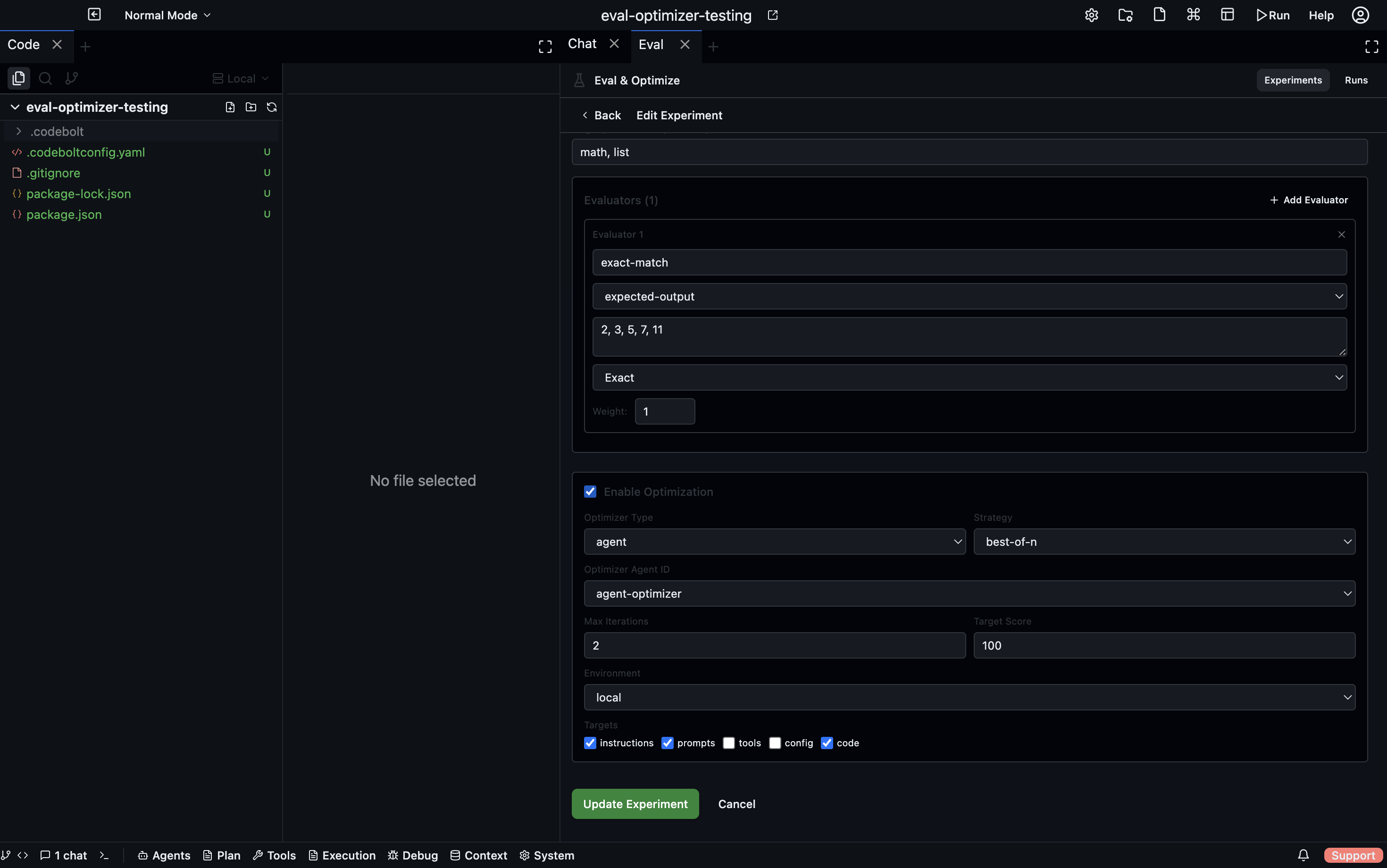
Evaluators
An evaluator inspects a subject's output after a task run and returns a score from 0 to 100, plus a reasoning string explaining the score. Each task can have multiple evaluators; their scores are combined into a single weighted average.
Scoring
final score = Σ(evaluator.score × evaluator.weight) / Σ(weights)
Each evaluator has a weight you set when adding it to a task. A weight of 2 makes that evaluator count twice as much as one with weight 1. Weights are relative — only the ratios matter.
Every evaluator result includes:
- score — normalised 0–100
- rawScore — original value before normalisation (varies by evaluator type)
- reasoning — explanation produced by the evaluator
Evaluator types
Expected Output
Compares the subject's output against a target string you define on the task.
| Match mode | How it works |
|---|---|
exact | Output must match the expected string exactly (100 or 0) |
contains | Output must contain the expected string (100 or 0) |
regex | Output must match a regular expression (100 or 0) |
semantic | An LLM judge decides how semantically similar the output is to the expected (0–100) |
Use exact or contains for deterministic, structured outputs. Use semantic when you care about meaning rather than exact wording.
Script
Runs a shell script that you write. The subject's output is provided as the environment variable EVAL_OUTPUT. Your script prints a JSON object to stdout:
{ "score": 85, "reasoning": "The agent correctly identified all three issues but missed the severity ranking." }
Score range: whatever your script returns (0–100).
Use Script evaluators for custom logic — checking file contents the agent wrote, running a test suite against the agent's code, calling an external API to validate the result, etc.
#!/bin/bash
# Example: run jest tests against the agent's code
cd /workspace
npm test -- --json 2>/dev/null | python3 -c "
import json, sys
data = json.load(sys.stdin)
passed = data['numPassedTests']
total = data['numTotalTests']
score = int(passed / total * 100)
print(json.dumps({'score': score, 'reasoning': f'{passed}/{total} tests passed'}))
"
Agent Judge
Spawns a judge agent to evaluate the output. The judge receives the task instruction, the subject's output, and any evaluation criteria you specify. It returns a JSON score and reasoning.
| Config | Description |
|---|---|
| Judge Agent | Which agent to use as the judge |
| Criteria | Natural language description of what to look for |
The judge agent sees:
- The original task instruction (what was asked)
- The subject's output (what was produced)
- Your criteria (what good looks like)
The judge then responds with a structured score. This evaluator is best for open-ended outputs where you need subjective reasoning — code quality, explanation clarity, tone, completeness.
Deliberation
Multiple agents discuss and vote on the output quality. Codebolt creates an agent deliberation session with four score brackets:
| Bracket | Score range |
|---|---|
| Poor | 0–25 |
| Fair | 26–50 |
| Good | 51–75 |
| Excellent | 76–100 |
Each participating agent votes for a bracket and explains its reasoning. The winning bracket determines the score. This evaluator produces a more robust assessment than a single judge for high-stakes or ambiguous tasks.
See Agent Deliberation for how the deliberation mechanism works.
Combining evaluators
A task can combine evaluator types. For example:
| Evaluator | Weight | Purpose |
|---|---|---|
| Script | 3 | Run automated tests — hard correctness signal |
| Agent Judge | 1 | Assess code quality — soft quality signal |
The script carries more weight here because automated test results are more reliable than subjective quality judgement. Adjust weights to reflect how much you trust each signal.